TL;DR
We expected AI to reduce toil. Every report, every vendor, every conference deck said the same thing. But when we looked at the data from 20+ industry reports and spoke to 25+ engineering teams, we found something different.
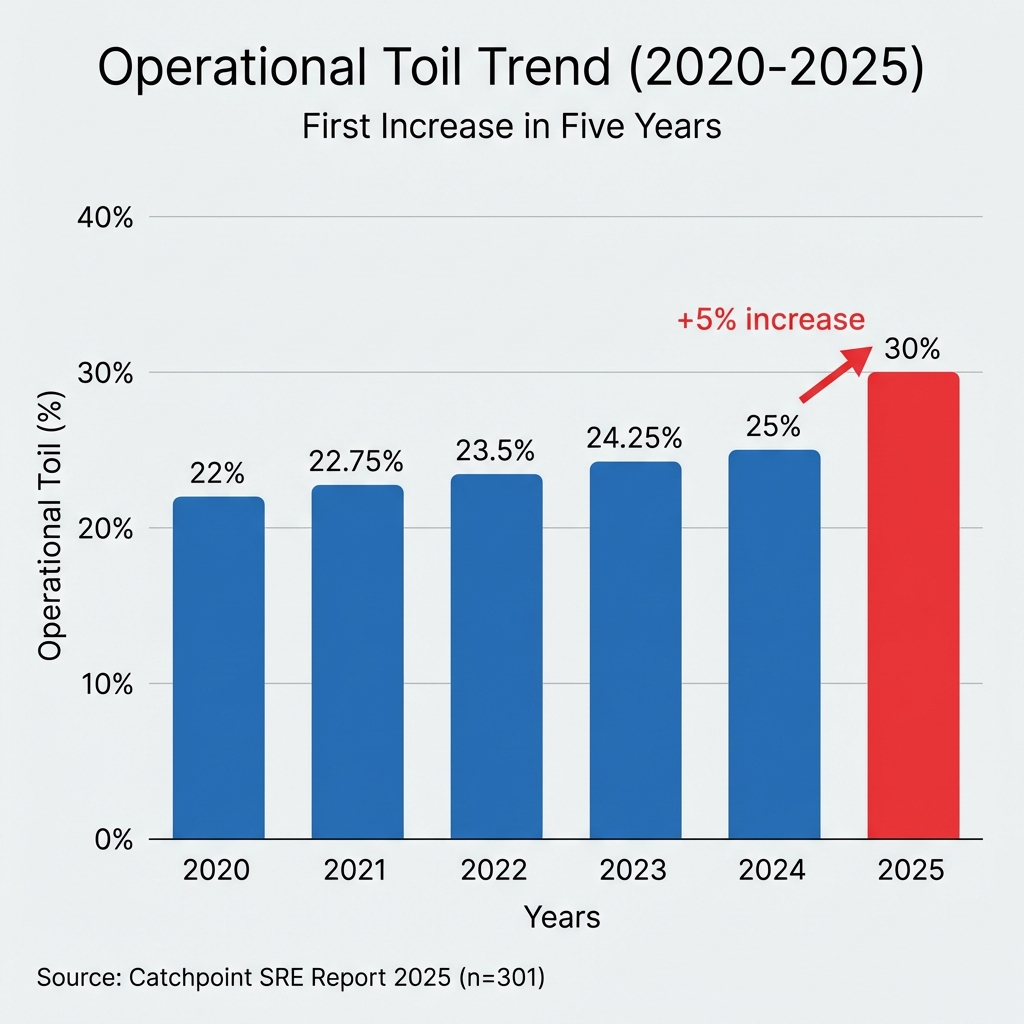
Toil rose to 30% (from 25%), the first increase in five years.
Here's what's actually happening in incident management right now:
AI isn't delivering (yet): Many organizations are investing $1M+ in AI initiatives (51% deployed, 86% expect to by 2027), yet operational toil rose from 25% to 30%. The first rise in five years.
People are burning out: 78% of developers spend ≥30% of their time on manual toil. 73% of organizations experienced outages linked to ignored alerts (Splunk, n=1,855). This isn't sustainable.
The market is consolidating fast: OpsGenie is scheduled to shut down in 2027. Freshworks acquired FireHydrant. SolarWinds acquired Squadcast. Organizations are moving from "best-of-breed" stacks to unified platforms because they can't manage 7+ tools anymore.
65% of organizations now say observability directly impacts revenue (Splunk). Incident management has to keep pace.
And here's the part nobody wants to hear: while executives expect 171% ROI from AI investments, the reality is more complexity, not less. Developer toil can cost ~$9.4M/year per 250 engineers (simplified model). The "AI revolution" has paradoxically increased the blast radius of bad deployments for 92% of teams.
And it's getting more expensive to get it wrong. High-impact IT outages now cost ~$2M/hour (New Relic Observability Forecast 2025, n=1,700). Organizations lose a median of ~$76M annually from unplanned downtime (New Relic Observability Forecast 2025).
This report synthesizes 20+ industry reports and surveys published in 2025.
Scope: This report focuses on SRE/engineering incident response and operational toil, not security operations (SOC).
The 2025 Incident Index
| Finding | Statistic | Source |
|---|---|---|
| AI agents deployed | 51% | PagerDuty, 2025 |
| Expect AI agents by 2027 | 86% | PagerDuty, 2025 |
| Expected ROI from AI | 171% avg | PagerDuty, 2025 |
| AI increases blast radius | 92% | Harness, 2025 |
| Toil percentage (up from 25%) | 30% | Catchpoint, 2025 |
| Devs spend ≥30% on toil | 78% | Harness, 2025 |
| Outages from ignored alerts | 73% | Splunk, 2025 |
| Developers work >40 hours/week | 88% | Harness, 2025 |
| Observability impacts revenue | 65% | Splunk, 2025 |
| High performers ROI advantage | +53% | Splunk, 2025 |
| High-impact outage cost per hour | $2M | New Relic, 2025 |
| Annual outage cost (median) | ~$76M | New Relic Observability Forecast 2025 |
| CrowdStrike global impact | ~8.5M devices, >~$5B economic impact | Parametrix, Reuters, 2024 |
About This Research
Methodology:
- 20+ industry reports analyzed
- 25+ engineering team interviews conducted July - December 2025 (Series A to enterprise, 30-60 minute structured interviews)
- Major incident analysis (CrowdStrike, AWS, OpenAI)
- Published: January 2026
Why we wrote this:
We're building Runframe after talking to 25+ engineering teams about their incident management pain. The conversations kept surfacing the same themes: AI isn't delivering, alert fatigue is crushing teams, tooling is too complex.
This report synthesizes what we heard from across the industry. Disclosure: we're building Runframe. We've aimed to keep the analysis vendor-neutral.
Who should read this:
- Engineering leaders evaluating incident management tools
- SREs dealing with alert fatigue and burnout
- CTOs planning 2026 tooling strategy
- Anyone migrating away from OpsGenie
1. The AI Trust Gap: Why Toil Rose to 30% (From 25%)
What executives are betting on
- 51% of companies have already deployed AI agents (PagerDuty Agentic AI Survey 2025, n=1,000)
- 86% expect to be operational with AI agents by 2027
- 75% of organizations are investing $1M+ in AI
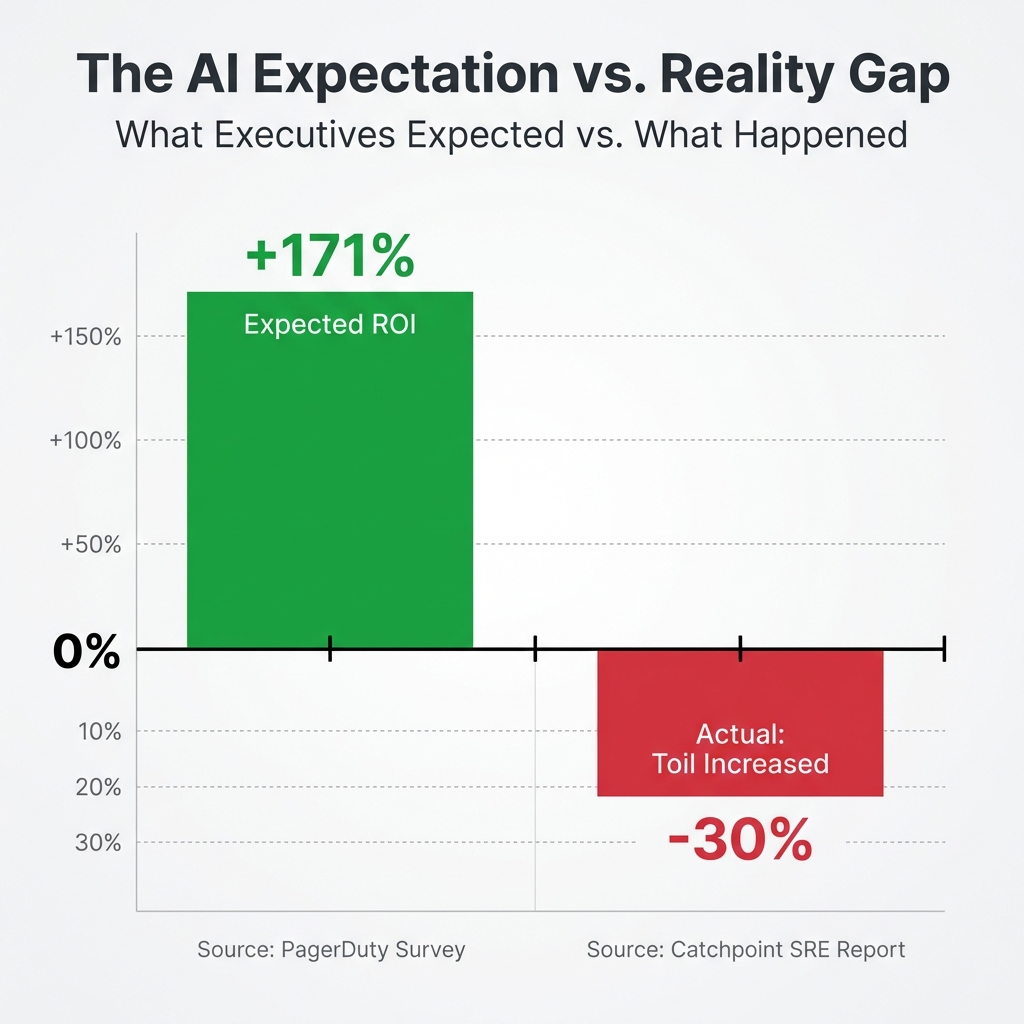
- 62% expect more than 100% ROI, with an average expected return of 171%
- 100% of organizations are now using AI in some capacity, and AI capabilities are now the #1 criterion for selecting observability tools (Dynatrace, n=842)
The hype is real. Executives are all-in.
What's actually happening
- Operational toil rose to 30% from 25%, the first rise in five years (Catchpoint SRE Report 2025, n=301)
- Enterprise incidents increased 16% YoY (PagerDuty State of Digital Operations 2024)
- 92% of developers say AI tools increase the "blast radius" from bad deployments (Harness State of Software Delivery 2025, n=500)
The first wave of AI deployments has added new layers of complexity: new tools to monitor, new alerts to triage, new skills to learn, and more code to review.
"What was most eye opening from our report findings this year was that, for most teams, it seems the burden of operational tasks has grown for the first time in five years. The expectation was that AI would reduce toil, not exacerbate it."
--Catchpoint SRE Report 2025
The implementation gap (not a tech failure)
- 69% of AI-powered decisions are still verified by humans (Dynatrace)
- 25% of leaders believe improving trust in AI should be a top priority
The technology isn't failing. Our implementation strategy is.
We're living through the awkward adolescence of AI. These are probably the worst versions of these models we'll ever use. Powerful, but prone to hallucinations, so humans still verify almost every action.
The rise to 30% in toil isn't because AI is bad. It's because we've added a "verification tax" on top of existing workloads without removing anything yet. Not fully autonomous, but no longer purely manual. The messy middle.
The rise of agentic AI in SRE
Multi-agent systems are now being deployed for complex incident resolution. AWS and others are shipping "agent" concepts aimed at reducing time-to-triage and time-to-mitigate (early-stage; outcomes vary). Platforms like Rootly, Harness, and PagerDuty are shipping AI-powered runbook execution and autonomous triage capabilities.
The future of AI in incident management is human-in-the-loop, not fully autonomous. AI suggests, humans approve.
Takeaway: Organizations invested heavily in AI expecting reduced toil. Instead, toil rose to 30% (the first rise in five years). The AI correction phase is coming in 2026.
2. The Burnout Tax: The $9.4M Cost of Silence
The $9.4M annual waste nobody talks about (Simplified Model)
- 78% of developers spend at least 30% of their time on manual, repetitive tasks (Harness)
- Average software engineer salary: $125,000 (Indeed, Glassdoor, ZipRecruiter) (varies widely by market/level; treat ranges as directional)
- 30% toil × $125,000 = $37,500 of wasted investment per engineer annually
- For organizations with 250+ engineers: ~$9.4M in lost productivity annually (simplified model: assumes $125k avg salary, 30% time on toil; actual costs vary by geography, role mix, and toil type) . See our build vs buy analysis for how these costs compare when building custom tooling
In our interviews, developers said the same things: frequent overtime leads to burnout, steals time from family, and eventually pushes them to leave.
For more on sustainable on-call rotations, see our On-Call Rotation Guide.
Alert fatigue increases the chance of missed signals
- 73% of organizations experienced outages linked to ignored or suppressed alerts (Splunk State of Observability 2025, n=1,855)
- Industry analyses suggest as many as 67% of alerts are ignored daily (incident.io blog; underlying primary dataset not published)
- Customer-impacting incidents increased 43%, each costing nearly $800,000 (PagerDuty Cost of Incidents study)
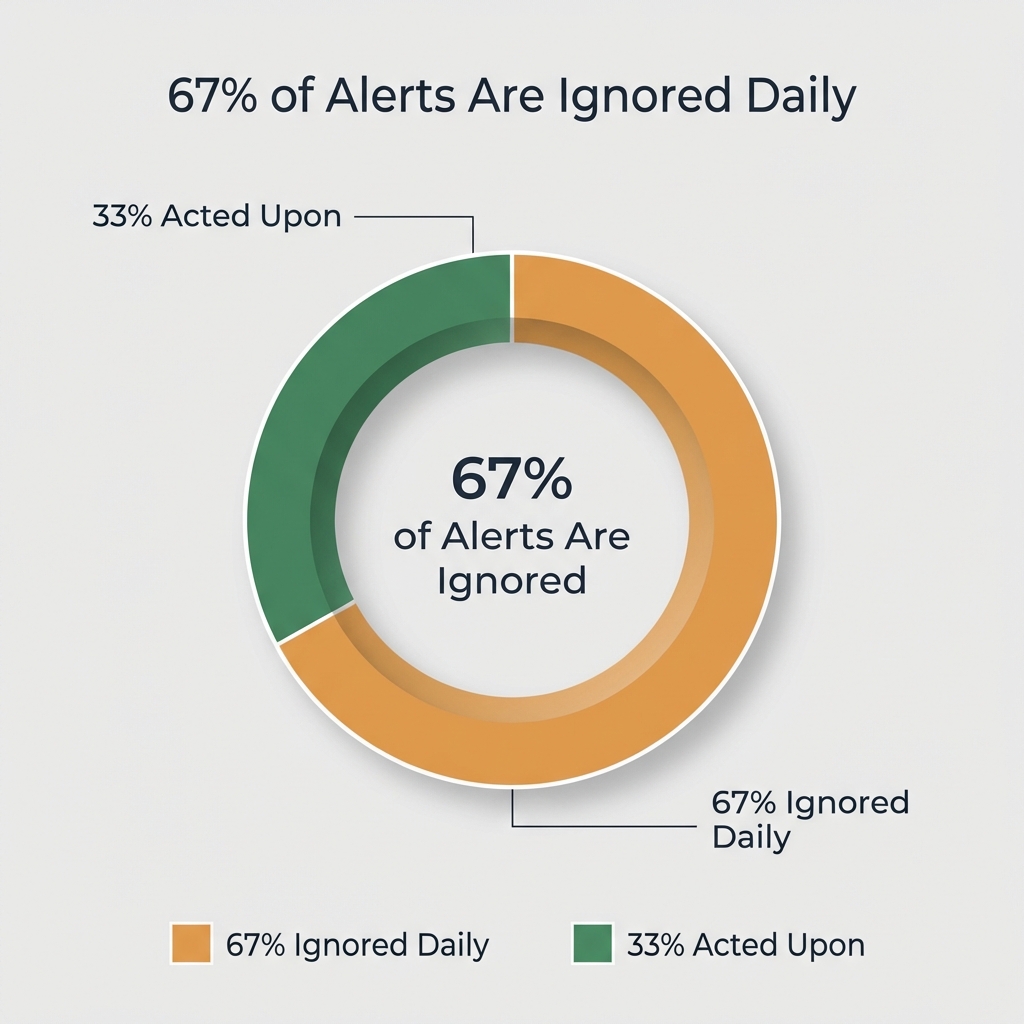
This is what we heard over and over in our interviews: teams are drowning in alerts. They've learned to ignore them. Then real incidents happen and nobody responds.
"Our on-call engineers get 200+ pages per week. Maybe 5 are real. The rest? Threshold noise, flapping alerts, things that auto-resolved. We've trained our team to ignore alerts, which is terrifying."
-- VP Engineering, Healthcare SaaS (160 engineers)
On-call burnout is at crisis levels
- Unstable organizational priorities lead to meaningful decreases in productivity and substantial increases in burnout (DORA 2024 Report)
The firefighting trap
- 20% say they often or always start a "war room" with members of many teams until an issue is resolved, and 43% spend too much time responding to alerts (Splunk State of Observability 2025, n=1,855)
- Teams are missing real signals in the noise. The ones that break out of this cycle prioritize alert hygiene: automated noise reduction, correlation, and routing alerts to the right person instead of everyone.
What this means: Alert fatigue increases the chance of missed signals. ~$9.4M/year lost per 250 engineers (simplified model). Burnout is at crisis levels. The 30-day rule: delete alerts nobody acts on.
3. The great consolidation: why best-of-breed is dead
Three acquisitions in 12 months
OpsGenie Shutdown (June 2025 - April 2027)
- June 4, 2025: No new OpsGenie accounts can be created
- April 5, 2027: Complete service shutdown
- Forcing thousands of organizations to evaluate alternatives
- Official Atlassian announcement | Read our migration guide
SolarWinds Acquires Squadcast (March 2025)
- Announced March 3, 2025
- Unifying observability and incident response
- Press release
Freshworks Acquires FireHydrant (December 2025)
- Freshworks acquiring FireHydrant's incident management platform
- Folding it into their IT service and operations portfolio
- Press release
Why this is happening
Nobody wants to manage 7 tools anymore. The integration points break, the licensing costs add up, and every new hire spends their first week learning logins. Vendors with unified data also have a real advantage building AI features, since they can correlate across the full incident lifecycle.
Teams are actively comparing incident.io vs. FireHydrant vs. PagerDuty. The OpsGenie shutdown deadline is accelerating migrations.
What this means: Three major acquisitions/shutdowns in 12 months. Teams are moving from 7-tool stacks to unified platforms because they have to.
Major incidents (2024-2025): why incident response mattered
Learn how to run incidents with clear roles and escalation in our Incident Response Playbook.
July 2024: CrowdStrike global outage, the $5B wake-up call
The Incident:
- Impact: ~8.5 million Windows devices crashed globally (Reuters, citing Microsoft)
- Duration: Some businesses recovered in hours; others took days
Business impact: Airlines grounded, hospitals disrupted, financial services halted; economic impact estimates exceed ~$5B (e.g., Parametrix analysis; methodologies vary)
Why Incident Response Was the Difference:
Organizations with established incident response processes recovered significantly faster. The difference wasn't technical architecture. It was whether anyone knew who was supposed to do what:
- Companies with pre-defined escalation paths knew who could authorize system-wide changes
- Teams with customer communication templates kept stakeholders informed instead of scrambling
- Organizations with incident command structures avoided decision paralysis
"The difference between a 2-hour outage and a 2-day outage wasn't the bug. It was how quickly teams could coordinate remediation, communicate with customers, and execute rollback procedures."
October 2025: AWS US-East-1 outage, coordination chaos
The Incident:
- Duration: ~15 hours (ThousandEyes)
- Impact: Services across multiple industries affected
- Business impact: Widespread service disruption; direct revenue impact varied by company
What Went Wrong:
For many organizations impacted by the outage, the breakdown wasn't infrastructure. It was incident response:
- Unclear ownership: Teams spent critical hours determining who was responsible for what
- Missing communication loops: Stakeholders learned about outages from social media, not internal updates
- No pre-defined response: Organizations improvised instead of executing established playbooks
The Lesson:
Multi-region strategies help, but they're useless without incident management discipline. Some industry analyses claim organizations with documented runbooks and clear roles reduced their MTTR by up to 60% compared to those improvising (Xurrent; treat as directional). Calculate your MTTR → Free MTTR Calculator
December 2024: OpenAI ChatGPT outage, the recovery challenge
The Incident:
- Duration: ~4 hours of global service disruption
- Impact: Millions of users unable to access ChatGPT, API, and developer tools
- Root cause: A new telemetry service deployment created Kubernetes circular dependencies (OpenAI status page)
The Hidden Story:
While OpenAI's official postmortem focused on the technical root cause, the incident illustrates a broader incident response challenge:
- Recovery complexity: When systems have circular dependencies, recovery requires coordinated decision-making across multiple teams
- Status communication: With millions of users affected, timely updates become critical, yet challenging without established communication protocols
- Break-glass dilemma: OpenAI noted they're implementing "break-glass mechanisms" for future incidents, highlighting that manual recovery procedures must be defined in advance, not improvised during an outage
The Lesson:
When complex infrastructure fails, the difference between a 2-hour outage and a 4-hour outage often comes down to incident response discipline: pre-defined recovery procedures, clear escalation paths, and established communication channels. Technical root causes will happen; response processes determine how long they impact your business.
The pattern: alert fatigue causes real outages
Multiple 2025 incidents shared a common contributing factor: real alerts were ignored because teams were drowning in noise.
- In our interviews, financial services teams reported outages extended by hours when preceding alerts were dismissed as noise
- Healthcare SaaS teams told us incidents were delayed 20-30 minutes due to "is this real?" debate. That's time that matters when patient care is at stake
- 73% of organizations report outages caused by ignored or suppressed alerts
Alert noise isn't a monitoring problem. It's an incident management problem. Without proper routing, noise reduction, and escalation, teams train themselves to ignore notifications. Then real incidents happen.
"We've built an incident management system that cries wolf. Actual humans are paying the price when real incidents occur."
What we heard firsthand
We interviewed 25+ engineering teams while building Runframe, from Series A startups to Fortune 500 enterprises. Here's what they told us.
On AI adoption
"We deployed Copilot company-wide expecting a 30% productivity boost. Six months in, we're spending more time reviewing AI-generated code than we saved writing it. The junior engineers are the most affected. They're accepting suggestions they don't fully understand."
-- Engineering Manager, Series C Fintech (150 engineers)
"The AI tools are great for boilerplate. But for incident response? We tried an AI runbook assistant and it confidently gave wrong commands during a P1. We turned it off that night."
-- SRE Lead, E-commerce Platform (80 engineers)
On alert fatigue
"Our on-call engineers get 200+ pages per week. Maybe 5 are real. The rest? Threshold noise, flapping alerts, things that auto-resolved. We've trained our team to ignore alerts, which is terrifying."
-- VP Engineering, Healthcare SaaS (160 engineers)
On DevOps burnout
"We lost three senior SREs in six months. All cited on-call burden. These are people with 10+ years of experience who could work anywhere. We couldn't retain them."
-- CTO, Infrastructure Startup (60 engineers)
"I asked my team what would make their lives better. Number one answer: 'Fewer tools.' We use 7 different systems to manage incidents. Seven."
-- Director of Platform, Media Company (120 engineers)
On what's actually working
"The single biggest improvement we made was deleting 80% of our alerts. Not tuning them — deleting. If nobody acts on an alert for 30 days, it's gone. Our MTTA dropped by 40%."
-- SRE Manager, Gaming Company (90 engineers)
"We stopped doing weekly on-call rotations. Moved to follow-the-sun with 3 regional teams. Burnout complaints dropped to almost zero."
-- Head of Reliability, Global SaaS (175 engineers)
On market consolidation
"With OpsGenie shutting down, we had to migrate 200+ users. We chose a Slack-native alternative that meant no context switching. Our MTTR dropped 25% in the first month."
-- DevOps Lead, Series B SaaS (75 engineers)
What this means for 2026
The data is sobering. But the market is correcting fast, and the problems are finally measurable enough that leadership is paying attention.
1. AI tools will actually work (finally)
The first wave of AI tools shipped features. The second wave needs to ship outcomes.
The metrics that matter will change. Not "lines of code generated" or "suggestions accepted," but "did operational toil go down?" Human-in-the-loop approval for high-impact changes will become standard because nobody wants an AI deleting production databases unsupervised. And instead of one monolithic "AI assistant," we'll see specialized agents: one for triage, one for RCA, one for remediation, one for comms. Each doing one thing well.
The ~$9.4M/year toil cost (simplified model) is too expensive to ignore. The organizations that win here will be the ones whose AI reduces complexity rather than adding to it.
Prediction (Confidence: Medium): Q2-Q3 2026. The first wave of AI that actually reduces toil ships.
2. Alert fatigue gets solved (it has to)
73% of organizations experienced outages because real alerts got lost in the noise. The tooling to fix this exists. Most organizations just haven't deployed it.
AI-powered alert correlation is shipping from Splunk, Dynatrace, and newer players. 200 alerts become 3 actionable incidents. Context-aware routing sends alerts to the right person based on who's on-call, who owns the service, who fixed it last time. Self-healing loops handle known issues (connection pool exhaustion, cache miss storms) automatically and only page humans when remediation fails.
At the org level, more teams will adopt the "30-day rule": if nobody acts on an alert for 30 days, delete it. Not tune it. Delete it. We've seen teams cut MTTA by 40%+ doing this alone.
The cost of ignoring alerts is now measurable. Leadership cares. Budget will follow.
Prediction: H1 2026. Alert fatigue becomes a board-level discussion.
3. Consolidation creates better tools (not worse)
The "best-of-breed" stack era created integration hell. Seven tools, seven logins, seven contexts to switch between. Consolidation forces the industry to fix that.
What replaces it: platforms that handle the full incident lifecycle without context switching, that work where your team already works (Slack, Teams), and that have open APIs instead of walled gardens. Not "one tool for everything" but fewer tools that actually talk to each other.
The OpsGenie shutdown is forcing thousands of teams to re-evaluate their entire stack, not just find a drop-in replacement. That's a chance to fix 5+ years of accumulated tool sprawl.
Prediction: Throughout 2026. The "great migration" happens.
4. Incident response becomes a discipline (not just firefighting)
Incident management has been "whoever's around figures it out" for most teams. That's changing because the cost of improvising is now visible.
Incident Commander is becoming a trained role, not just "whoever got paged." Runbooks are evolving from static docs into interactive decision trees ("Is the database responding? No -> Try this. Yes -> Check this."). And SLOs are going operational: 50% of organizations are investigating or implementing them (Grafana Observability Survey 2025).
CrowdStrike and AWS showed the gap clearly. Companies that recovered in hours had playbooks. Companies that took days didn't.
Prediction: 2026-2027. Industry-wide shift from reactive to proactive.
5. Agentic AI gets real (with guardrails)
The "autonomous agents" hype will settle into something practical: constrained automation for known scenarios, with human escalation for everything else.
What that looks like: AI can restart a service. It can't delete a database without someone approving it. Triage agent, RCA agent, remediation agent, each with clear scope and boundaries.
In practice:
Incident declared. Triage agent analyzes symptoms, suggests root cause. RCA agent pulls relevant logs, identifies the failing deployment. Remediation agent proposes: "Rollback to v2.3.1?" Human approves. Agent executes. Communication agent posts update to status page.
That's 20+ minutes of coordination saved. The technology exists. The models have gotten dramatically better. 2026 is when the tooling catches up.
Prediction: Late 2026. First production-ready agentic incident systems ship.
The bottom line
2025 was hard. Toil went up. Burnout is real. Alert fatigue is crushing teams.
But for the first time, the problems are measurable. And what gets measured gets fixed.
- ~$9.4M/year in developer toil (simplified model). CFOs care now.
- 73% had outages from ignored alerts. Boards care now.
- 88% of developers work >40 hours/week. Retention is threatened (Harness, 2025).
Prediction (Confidence: Medium): Toil drops back toward 25%. Alert noise decreases 50%+. First incident response platforms that actually reduce complexity ship in 2026.
What engineering teams should do in 2026
If you're drowning in alert noise
- Implement the 30-day rule: delete alerts nobody acts on for 30 days
- Deploy correlation tools (Splunk, Dynatrace, or alternatives)
- Measure your noise ratio. Target <20%
If your team is burning out
- Audit on-call rotation: are people working >40 hours + on-call?
- Implement recovery time: paged at 2 AM? Start late the next day
- Consider compensation: $200-400/week or TOIL
If you're managing 5+ incident tools
- List everything you use for monitoring, alerting, incident response, postmortems, on-call, status pages, and chat ops
- Calculate total cost (licenses + engineering time maintaining integrations)
- Evaluate unified platforms. The savings are usually bigger than expected
If you're migrating from OpsGenie
- Timeline: June 2025 = no new accounts, April 2027 = shutdown
- Key vendors to consider: PagerDuty, incident.io, and emerging platforms
- Prioritize Slack-native workflows, alert correlation, unified platform
- Read our complete OpsGenie Migration Guide for timelines, pricing, and step-by-step plans
If you're investing in AI
- Measure toil before and after deployment
- Implement human-in-the-loop for high-impact changes
- Track whether operational toil actually decreased, not vanity metrics like "lines of code generated"
Need help? Get started free | Read our blog
Sources
Industry Research Reports
- Splunk State of Observability 2025 — n=1,855 professionals
- Dynatrace State of Observability 2025 — n=842 senior leaders
- PagerDuty Agentic AI Survey 2025 — n=1,000 executives
- Harness State of Software Delivery 2025 — n=500 practitioners
- Catchpoint SRE Report 2025 — n=301 professionals
- New Relic Observability Forecast 2025
- DORA Report 2024 — Google Cloud
Additional Sources
- Atlassian State of Incident Management 2024 — n=500+ practitioners
- PagerDuty State of Digital Operations 2024
- PagerDuty Cost of Incidents Study
- DevOps.com Burnout Survey 2024
Major Incidents & Case Studies
- CrowdStrike Global Outage — Microsoft estimate (Reuters) — July 2024
- AWS US-East-1 Outage Analysis (ThousandEyes) — October 2025
- OpenAI Outage Postmortem (OpenAI status) — December 2024
Market News
- OpsGenie Shutdown - Official Atlassian Announcement
- SolarWinds Acquires Squadcast
- Freshworks Acquires FireHydrant
Report Highlights
75% of organizations invest $1M+ in AI expecting 171% ROI. Operational toil rose for the first time in five years.
78% of developers spend 30%+ of their time on manual toil. For a 250-person team, that's ~$9.4M/year (simplified model).
73% of organizations had outages linked to ignored alerts (Splunk, n=1,855). ~67% of alerts may be ignored daily (incident.io blog; underlying dataset not published).
High-impact IT outages cost ~$2 million per hour. Organizations lose a median of ~$76 million annually from unplanned downtime.
About This Report
This research was compiled by the Runframe team. Published January 2026.
We're building Runframe because the problems in this report are real. If your team is dealing with alert fatigue, tool sprawl, or burnout, get started free at runframe.io.