Incidents happen.
Chaos doesn't have to.
Incident management, on-call scheduling, and postmortems. All in Slack, where your team already lives.
On-call included in every plan. Not an add-on.
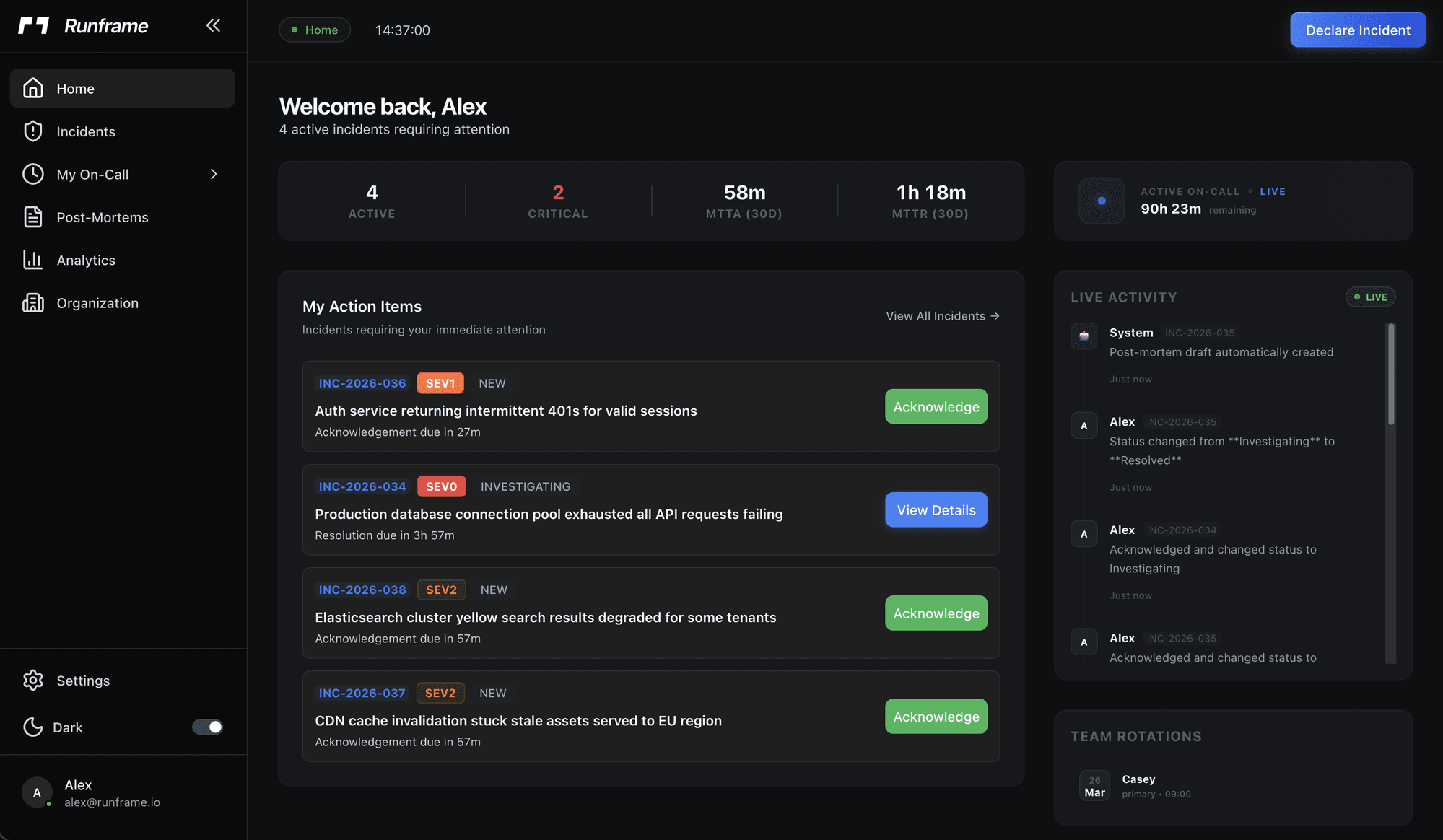
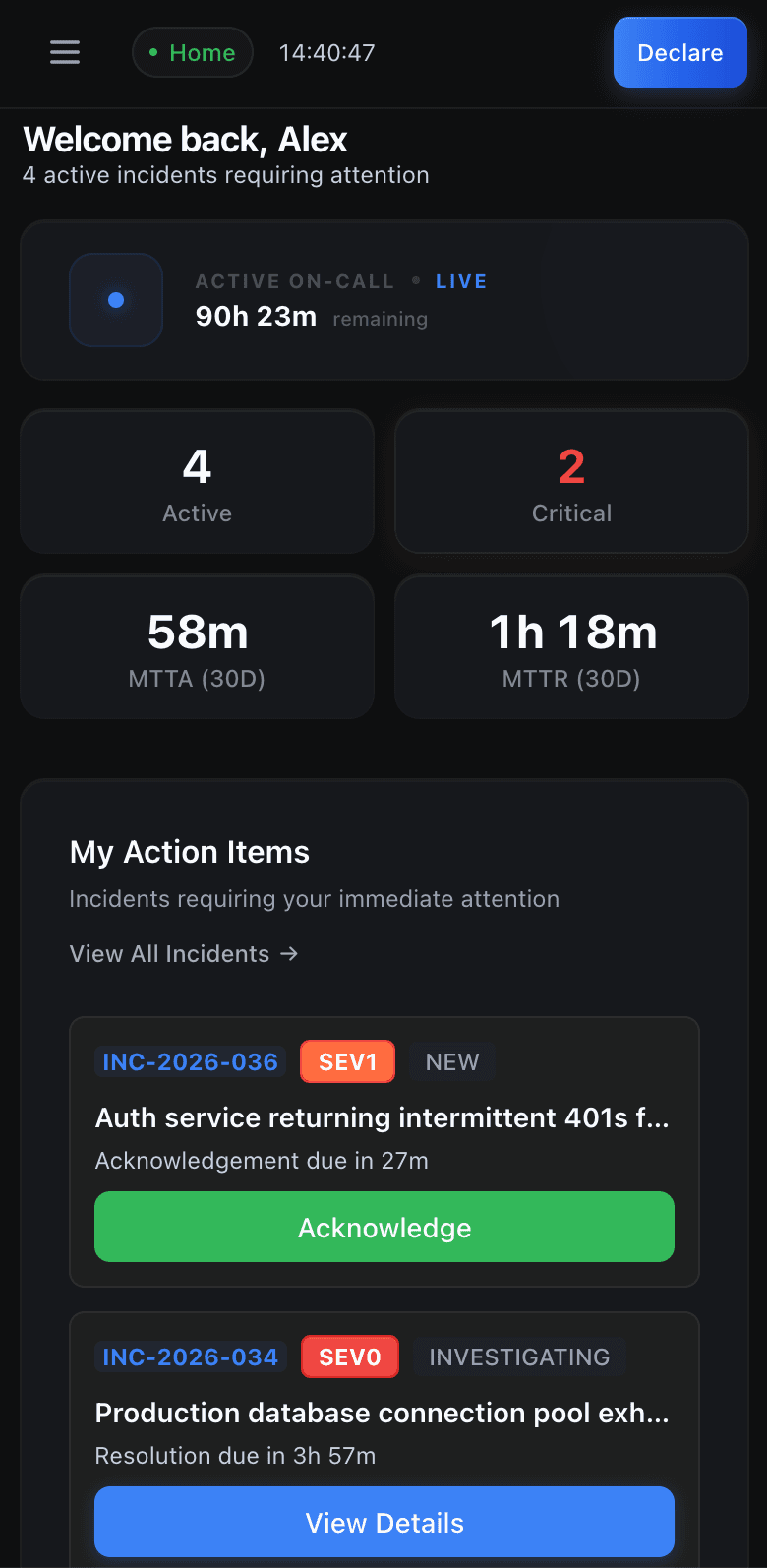
Stop switching between five tools
during an outage.
Nobody knows who's on-call. The escalation policy is tribal knowledge. Postmortems get written two weeks late, if at all.
One platform. Zero context switching.
Your incident war room is already open.
Type /inc in any Slack channel to declare an incident. Runframe creates a channel, notifies the on-call engineer, and tracks every message and status change until it's resolved.
Triage, escalate, acknowledge, and resolve without leaving Slack. The timeline writes itself. No manual updates.
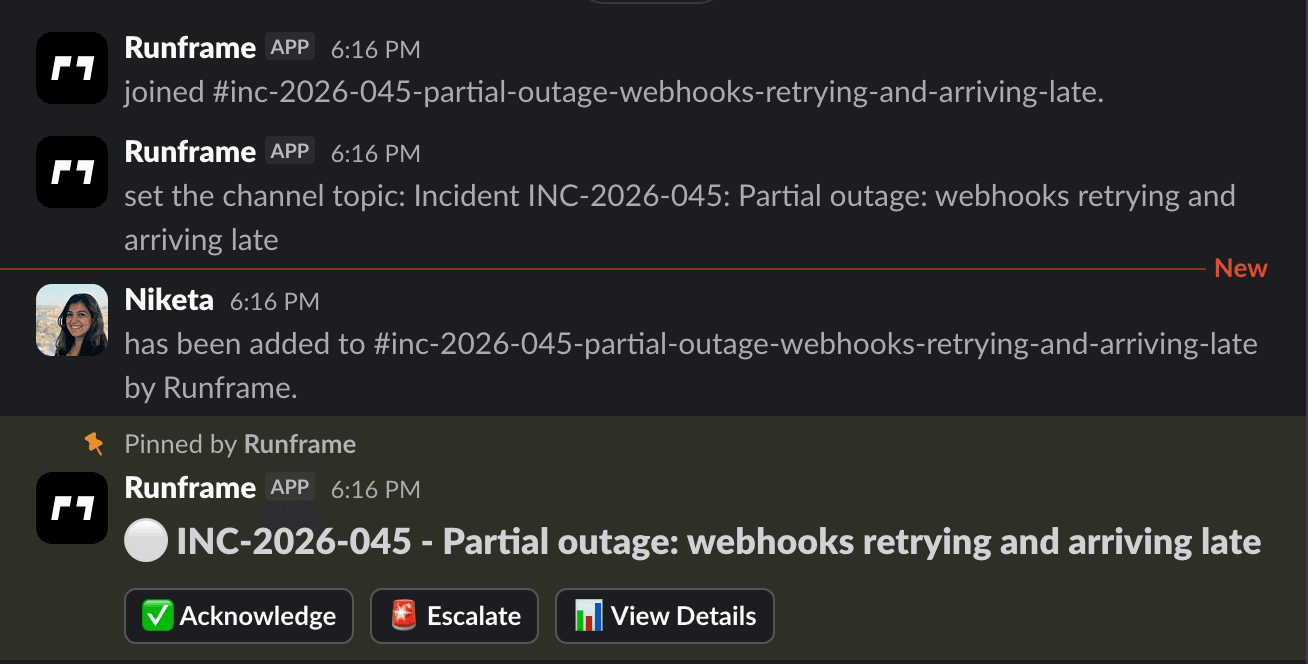
How it works
Three steps. That's it.
Alert comes in
Datadog fires, Prometheus trips, or someone types /inc in Slack. Runframe creates a dedicated incident channel and pages the on-call engineer.
Team responds
The commander acknowledges, assigns roles, and runs the incident from Slack. Every status change, escalation, and message is captured in the timeline automatically.
Resolve and learn
Mark it resolved. Runframe generates a postmortem draft with the timeline and actions already filled in. Review it, don't reconstruct it.
Incidents
Declare an incident and Runframe creates a Slack channel, assigns a commander, and starts the clock. Every message, status change, and escalation goes into the timeline. When it's resolved, the postmortem is already half-written.
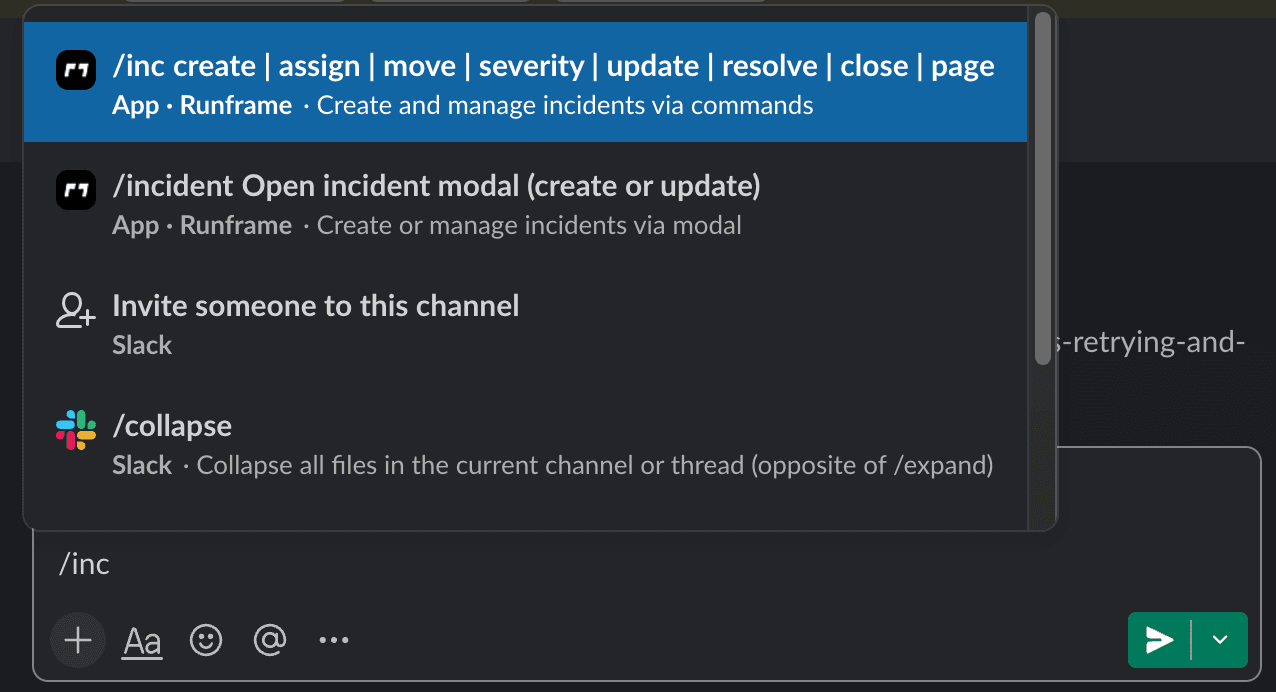
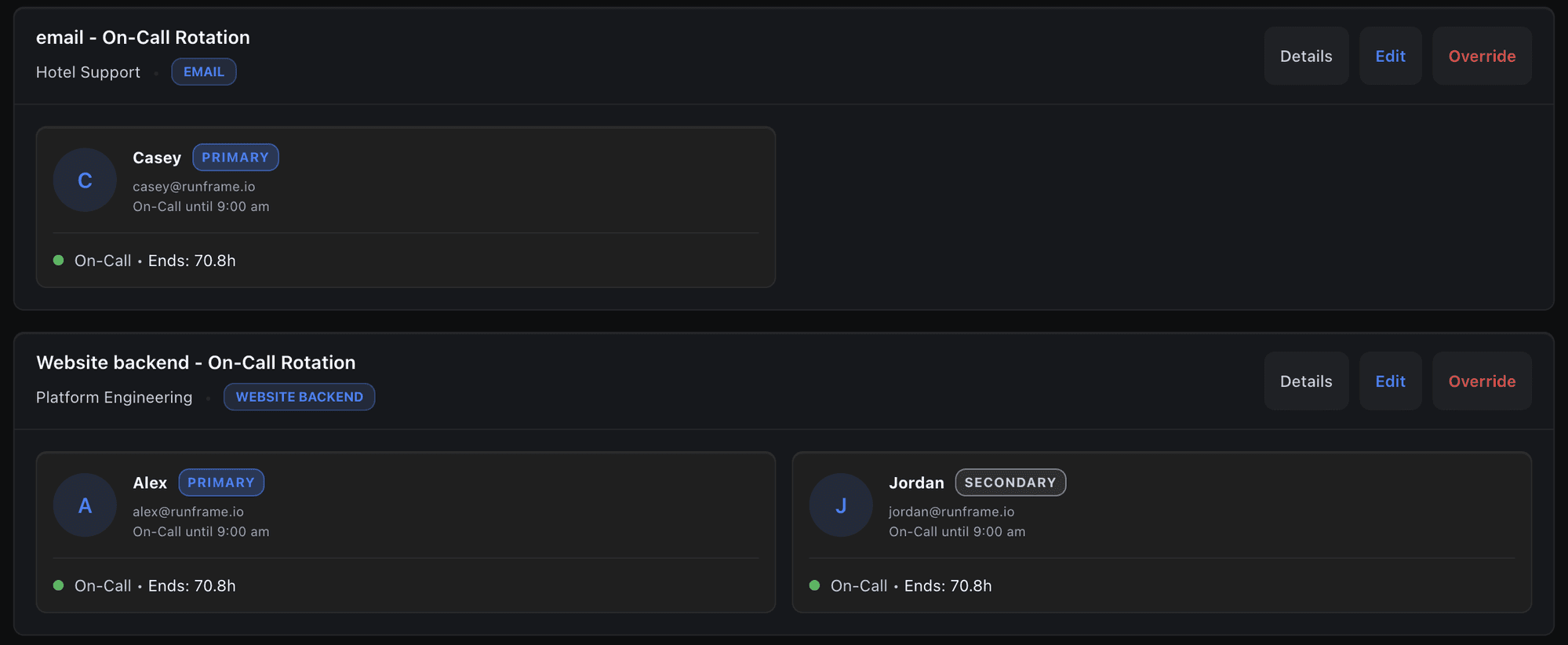
On-call
Set up daily, weekly, or monthly rotations in minutes. If the on-call engineer doesn't acknowledge, Runframe pages the next person. Your team sees who's on-call right now, not in a spreadsheet buried in Google Drive.
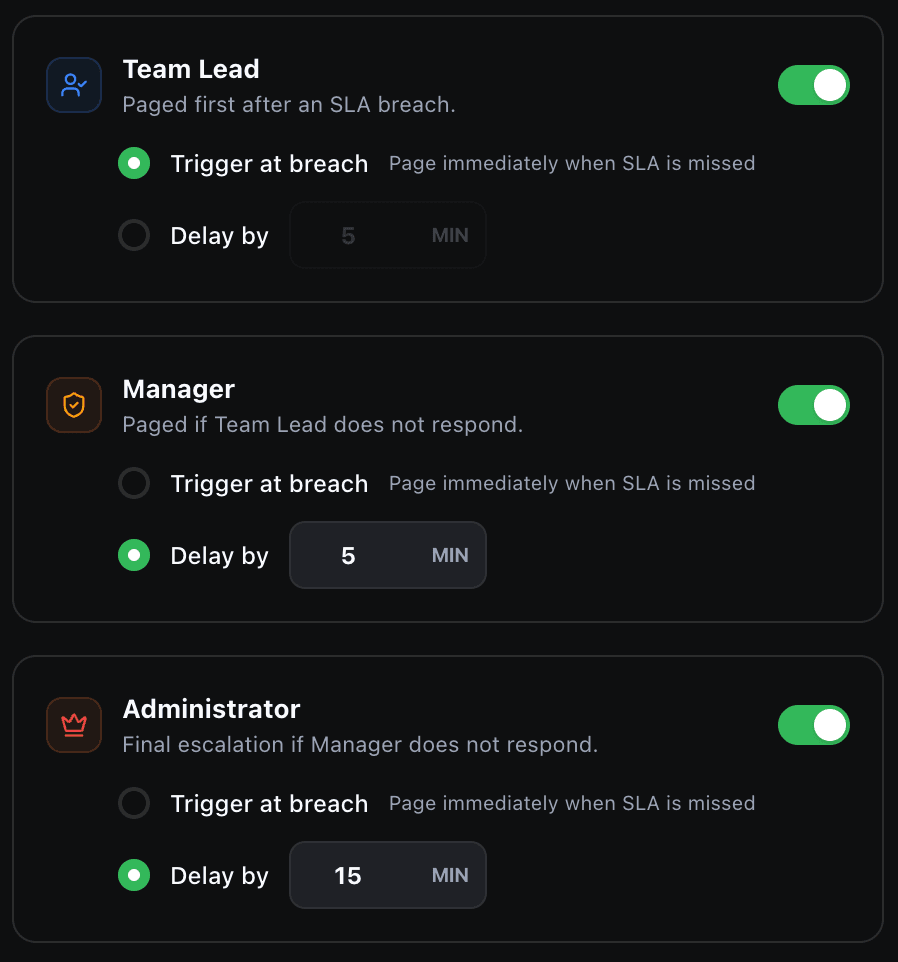
Escalations
Define who gets paged first, who's backup, and how long to wait before escalating. If L1 doesn't acknowledge in 5 minutes, L2 gets paged automatically. No more @channel in Slack hoping someone responds.
Enterprise security, startup speed.
Enterprise Security
Industry-standard protections. Your data remains yours, never shared with third parties.
End-to-End Encryption
Data encrypted in transit and at rest. AES-256 encryption. HTTPS everywhere.
Role-Based Access
Granular permissions per feature. Control who can create incidents, modify schedules, or view analytics.
Comprehensive Audit Logs
Full activity tracking. Every action logged with user, timestamp, and context. Export for SOC 2 prep.
Plug into what you already use.
Webhook-based integrations. No agents to install, no complex configuration.
Common questions
Your next outage is coming. Be ready.
Set up Runframe in under 10 minutes. Free for teams up to 5. No credit card.